



大模型新时代,小公司靠边站?(组图)
Meta旗下第三代大模型Llama 3终于在本周正式亮相:最大参数规模超4000亿,训练token超15万亿,对比GPT-3.5多种人类评估测评胜率超六成,官方号称“地表最强开源模型”。
在各大科技巨头的“内卷”中,大模型终于来到了一个关键的转折点。摩根士丹利指出,世界正在进入一个由硬件和软件共同推动的大模型能力快速增长的新时代,大模型在创造力、战略思维和处理复杂多维任务方面的能力将显著提升。
报告强调,未来大模型的训练将需要前所未有的算力,这将导致开发成本显著增加。摩根士丹利Stephen C Byrd分析师团队在本周公布的报告预计,训练下一代大模型所需的超级计算机成本之高企,即使对于科技巨头来说也是一个巨大的挑战,更别提小公司了。
报告进一步指出,除了高昂的资本支出外,芯片电力供应和人工智能技术的壁垒也在增加。这些因素共同构成了进入大模型领域的重大障碍,可能会使得小公司难以与强大的巨头企业竞争。
因此,摩根士丹利对谷歌、Meta、亚马逊和微软等大型科技公司给予了增持评级,这些公司凭借其在技术、资本和市场上的优势,有望在大模型的发展中占据领先地位。与此同时,小公司虽然可能在大模型的世界被边缘化,但成本更低的小模型将为它们创造新的机会。
 未来算力指数级增长,英伟达是关键?
未来算力指数级增长,英伟达是关键?
摩根士丹利指出,在不久的将来,开发大模型所需的算力将实现指数级的增长,这一增长与芯片技术的进步紧密相关,英伟达“史上最强芯片”Blackwel是推动算力增长的关键技术之一。
以OpenAI训练GPT模型为例。
摩根士丹利指出,目前训练GPT-4需要大约100天的时间,使用2.5万个英伟达A100 GPU,处理13万亿个token,并且涉及大约1.76万亿个参数。
这些A100 的总算力(以FP8 teraFLOPs衡量)大约是1600万。teraFLOPs是衡量浮点运算性能的单位,表示每秒可以执行多少万亿次浮点运算。GPT-4训练所需的总浮点运算次数约为137万亿次。
对于即将亮相的GPT-5,摩根士丹利预计,该模型的训练需要部署20万-30万个H100 GPU,耗时130-200 天。

超级计算机将使指数级的增长预期更加容易实现。摩根士丹利模型显示,本十年晚些时候超级计算机为开发大模型提供的算力比当前水平高1000倍以上。
使用Blackwell的超级计算机,只需要150-200天的训练时间,就能开发出一个全新的大模型,与当前大模型(如GPT-4)相比,其提供的算力,比当前模型所需高出1400-1900倍。
报告还提到,未来GPT-6所需的年度算力,将占英伟达芯片年销售额的相当大的百分比。预计使用B100或H100 GPU的100兆瓦数据中心的成本可能为15亿美元。
摩根士丹利将英伟达视为算力增长的关键驱动力。
根据预测,从2024年到2026年英伟达算力将以70%的复合年增长率增长。这个增长率是基于SXM(可能是NVIDIA的某个产品或服务的代号)和FP8 Tensor Core(一种性能指标)来计算的。
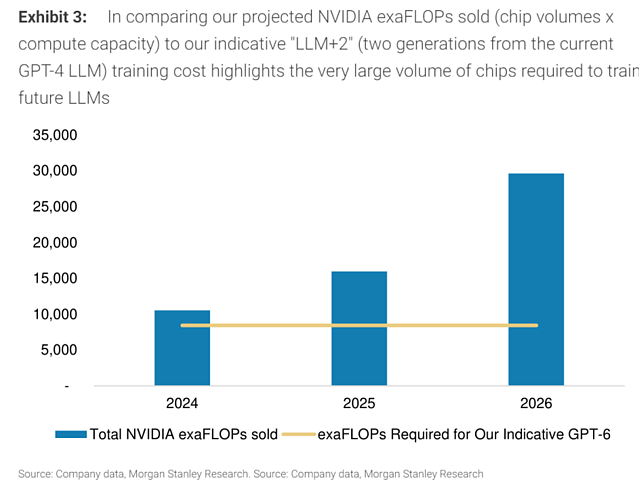
 大模型时代,科技巨头是最大受益者?
大模型时代,科技巨头是最大受益者?
然而,开发超强大模型及其训练所需的超级计算机涉及到一系列复杂的挑战,包括资本投入、芯片供应、电力需求和软件开发能力。这些因素构成了进入这一领域的主要壁垒,将使那些资本雄厚、技术领先的科技巨头获得更多机会。
资本投入方面,摩根士丹利将谷歌、Meta、亚马逊和微软在2024年的数据中心资本支出进行了比较,对象是一系列不同规模的超级计算机,其中1吉瓦的超级计算机设施的估算成本约为300亿美元,而更大规模的超级计算机的成本可能高达1000亿美元。
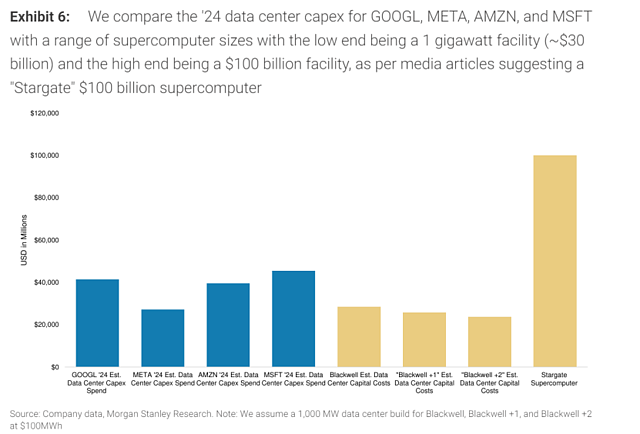
摩根士丹利预计,这四家美国超大规模计算公司在2024年和2025年的数据中心资本支出将分别达到约1550亿美元和超过1750亿美元。这些巨额数字将使小企业望而却步。
该机构还认为谷歌、Meta、亚马逊和微软将是算力增长的直接受益者,给予四家公司增持评级。
 小公司的机会在哪里?
小公司的机会在哪里?
尽管小公司可能在更加复杂的大模型的开发中被边缘化,但小模型的发展将为它们创造新的机会。
摩根士丹利表示,小模型的开发成本较低,未来可能在特定的行业领域中实现显著的好处,并推动通用人工智能技术的快速普及。
我们最新的通用人工智能模型包括一个可以计算训练小模型相关数据中心成本的工具,我们认为这是评估特定领域小模型可能扩散的回报率(ROIC)的一个有益起点。
我们认为小模型成本的下降和能力的提高,加强了我们对通用人工智能技术在许多领域采用的评估。
 软件加持下,未来的大模型能做什么?
软件加持下,未来的大模型能做什么?
值得注意的是,除了芯片等硬件方面的进步之外,软件架构的创新也将在推动大模型能力提升方面发挥关键作用,特别是Tree of Thoughts架构。
该架构由谷歌 DeepMind和普林斯顿大学的研究人员在2023年12月提出,设计灵感来源于人类意识的工作方式,特别是所谓的“系统2”思维。“系统2”是一种长期的、高度深思熟虑的认知过程,与快速、无意识的“系统1”思维相对,后者更类似于当前大模型的工作方式。
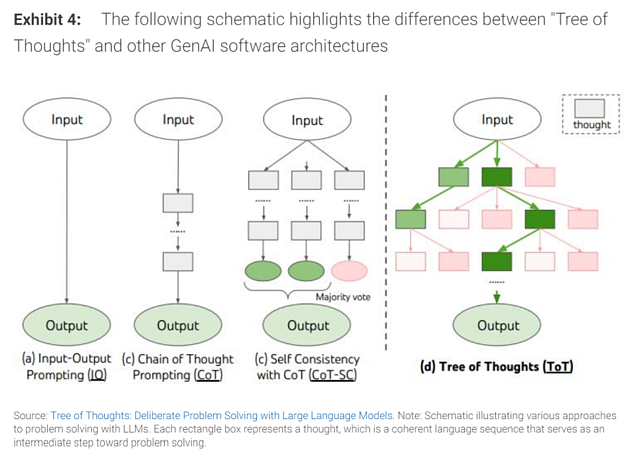
这一转变将使大模型能够以一种更类似于人类思考过程的方式来工作,突出了AI更强的创造力、战略思维和复杂、多维任务的能力。
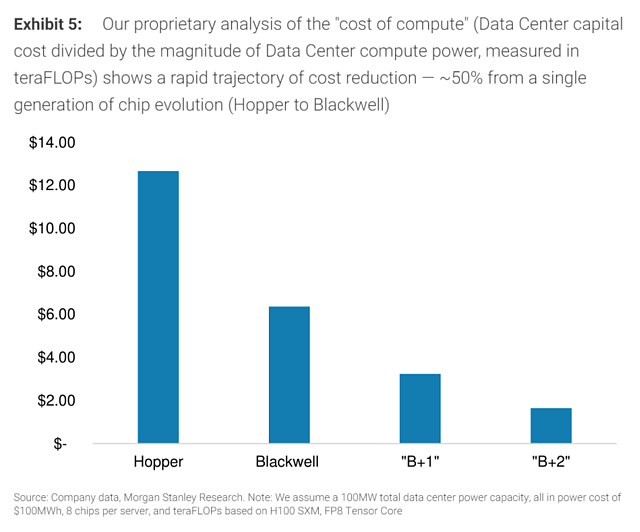
 计算成本大幅下降
计算成本大幅下降
摩根士丹利的专有数据中心模型预测,大模型算力的快速上升,意味着计算成本将快速降低。从单一芯片代的进化(从英伟达Hopper到Blackwell)来看,计算成本下降了大约50%。
OpenAI首席执行官Sam Altman此前强调了计算成本下降的重要性,并将其视为未来的关键资源,他认为算力可能成为世界上最宝贵的商品,重要性堪比货币。
此外,报告预测,将建造少数几台非常大的超级计算机,最有可能建在现有的核电站附近。
在美国,摩根士丹利预计宾夕法尼亚州和伊利诺伊州是开发超级计算机的最佳地点,因为这些地区有多个核电站,能够支持多千兆瓦的超级计算机的能源需求。




 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


